I’m going to use this blog post as a dynamic list of performance optimizations to consider when using Azure Data Factory’s Mapping Data Flow. I am going to focus this only to Azure SQL DW. I will post subsequent articles that list ways to optimize other source, sinks, and data transformation types. As I receive more good practices, feedback, and other performance tunings, I will update this article accordingly.
Here is Azure SQL DB Optimizations for ADF Data Flows.
Optimizations to consider when using ADF Mapping Data Flows with Azure SQL DW
NOTE: When you are designing and testing Data Flows from the ADF UI, make sure to turn on the Debug switch so that you can execute your data flows in real-time without waiting for a cluster to warm up.
Image may be NSFW.
Clik here to view.
You can match Spark data partitioning to your source database partitioning based on a database table column key in the Source transformation
Image may be NSFW.
Clik here to view.
- Go to “Optimize” and select “Source”. Set either a specific table column or a type in a query.
- If you chose “column”, then pick the partition column.
- Also, set the maximum number of connections to your Azure SQL DW. You can try a higher setting to gain parallel connections to your database. However, some cases may result in faster performance with a limited number of connections.
Set Batch Size and Query on Source
Image may be NSFW.
Clik here to view.
- Setting batch size will instruct ADF to store data in sets in memory instead of row-by-row. It is an optional setting and you may run out of resources on the compute nodes if they are not sized properly.
- Setting a query can allow you to filter rows right at the source before they even arrive for Data Flow for processing, which can make the initial data acquisition faster.
Use staging to load data in bulk via Polybase
- In order to avoid row-by-row processing of your data floes, set the “Staging” option in the Sink settings so that ADF can leverage Polybase to avoid row-by-row inserts into DW. This will instruct ADF to use Polybase so that data can be loaded in bulk.
- When you execute your data flow activity from a pipeline, with Staging turned on, you will need to select the Blob store location of your staging data for bulk loading.
Set Partitioning Options on your Sink
Image may be NSFW.
Clik here to view.
- Even if you don’t have your data partitioned in your destination Azure SQL DW tables, go to the Optimize tab and set partitioning.
- Very often, simply telling ADF to use Round Robin partitioning on the Spark execution clusters results in much faster data loading instead of forcing all connections from a single node/partition.
Set isolation level on Source transformation settings for SQL datasets
- Read uncommitted will provide faster query results on Source transformation
Image may be NSFW.
Clik here to view.
Increase size of your compute engine in Azure Integration Runtime
Image may be NSFW.
Clik here to view.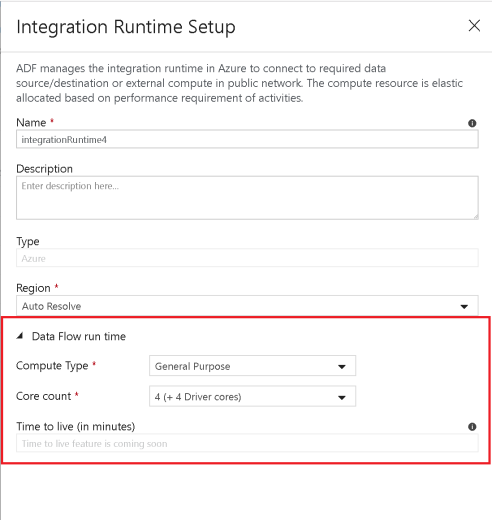
- Increase the number of cores, which will increase the number of nodes, and provide you with more processing power to query and write to your Azure SQL DW.
- Try “Compute Optimized” and “Memory Optimized” options
Disable indexes on write
- Use an ADF pipeline stored procedure activity prior to your Data Flow activity that disables indexes on your target tables that are being written to from your Sink.
- After your Data Flow activity, add another stored proc activity that enabled those indexes.
Increase the size of your Azure SQL DW
- Schedule a resizing of your source and sink Azure SQL DW before you run your pipeline to increase the throughput and minimize Azure throttling once you reach DWU limits.
- After your pipeline execution is complete, you can resize your databases back to their normal run rate.